Deep Learning
Prologue
As we mentioned in previous sections, the pipeline of image recognition can be polished by reconsidering its workflow. Now it looks as shows in figure:
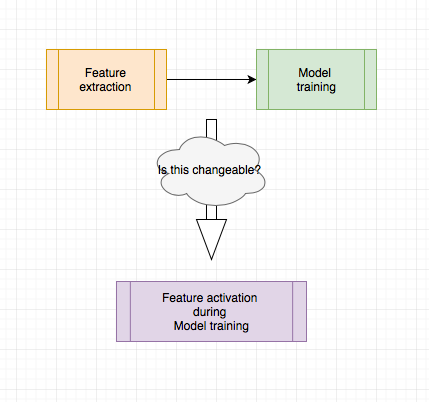
After the image is preprocessed as needed, the features will be extracted. Then these features are used for model training. This is actually so called Shallow Learning, which focuses on the expert knowledge in image processing in our task. It’s kind of limitation here, cause the learning results also intensively depends on the feature selection part. In contrast to shallow learning, Deep Learning is raw data-oriented representation learning approach. It’s normally supplied by the data in the raw form. There inputs are passed through a parametrized computational graph that’s much more representational. This graph usually has many layers and optimized by gradient-based schema. During the training the important features will be activated by this computational graph without extra feature extraction process. Now the most popular deep visual learning model is Convolution Neural Network. Let’s throught it out briefly.
Convolution Neural Network
Comparing with densely connected feed forward neural network, convolution neural network (CNN) needs much few parameter. At one side it use sparsely connections in neural layers, at another side the subpooling mechanisim provides a probability to share parameters between neurons. I’m not going to depict is deeply, cause there are lots of articals talk about theoretically. You’d better to inform them yourself.Brielfy to say, it works af follows.
Forward propagation
With a convolution filter with fixed size the input neurons are not fully connected with the inputs. From it the feature will be activated. These features will be subsampled in subsampling layers. There are two subsampling strategies: Mean-Pooling, which calculates the mean in a pooling filter size. Max-Pooling determines the maximum of the activated maps in a pooling filter size. After subpooling the results will be continuously convoluted as needs. The activated maps after - convolution layers are connected densely with feed forward neural network as we used before. The class scores are calculated in the last dense layer by using Entropy loss. With convolution operation and subpooling the parameters share there weight in a filter size. It’s called weight-sharing.
Backward Propagation
The scores is back propagated from last layer to the first convolution layer. For learning such a network by means of training examples, it turns to learn a input-output pattern correspondingly. The information of training samples is usually not sufficient by itself to reconstruct the unknown input-output mapping uniquely. Therefore we have to face the Overfitting problem. To conquer this issue we may use the regularization method. Normally it has the following definition:
In our case the empirical cost is the entropy cost we got and we use regularization as regularizer. The regularization paremeter is determined normally by validation design.
Implementation
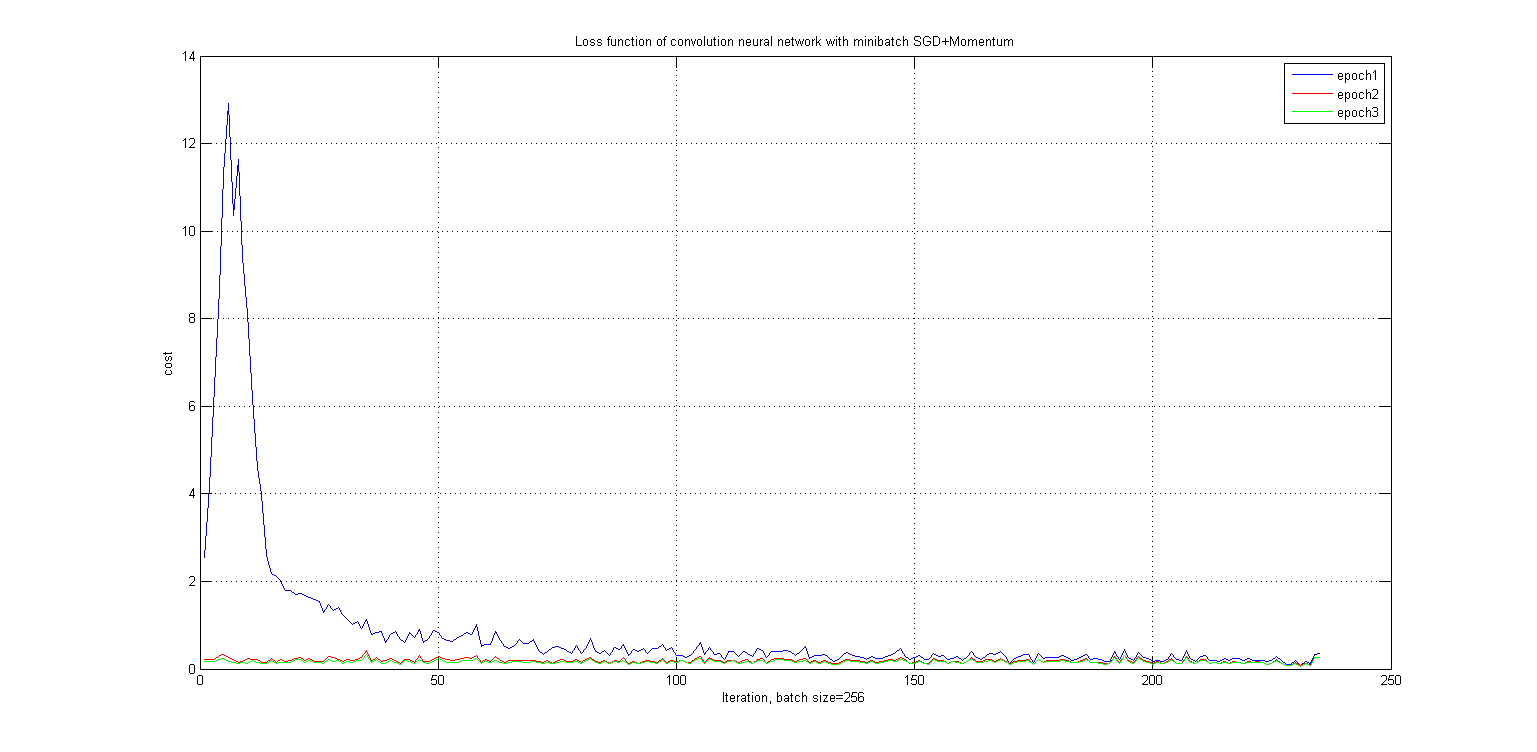
After showing the necessary techniques in deep learning consicely, let’s go back to our classification problem. Here I used one convolution layer and a mean-pooling layer. The sub pooled features will be fed to a dense neural layer. Its strcuture is very simple. For optimizing the computational graph I used the Stochastic Gradient Descent SGD+Momentum. Ususally the SGD works alone well, but at the saddle points the cost function nudges very hesitated. In order to make the learner lernens effectively, the Momentum is introduced. As in following figure depicts, the cost function has benn reduced ineffectively at the first 20 iteration in first epoch. After then it converges very smoothly.

As the input singal got forward propagated, the features turn to be much form or object oritend. I’m not showing here that this structur is the best design. But it works for some numbers even better than MLP + HoG we trained previously as shows in the following figure
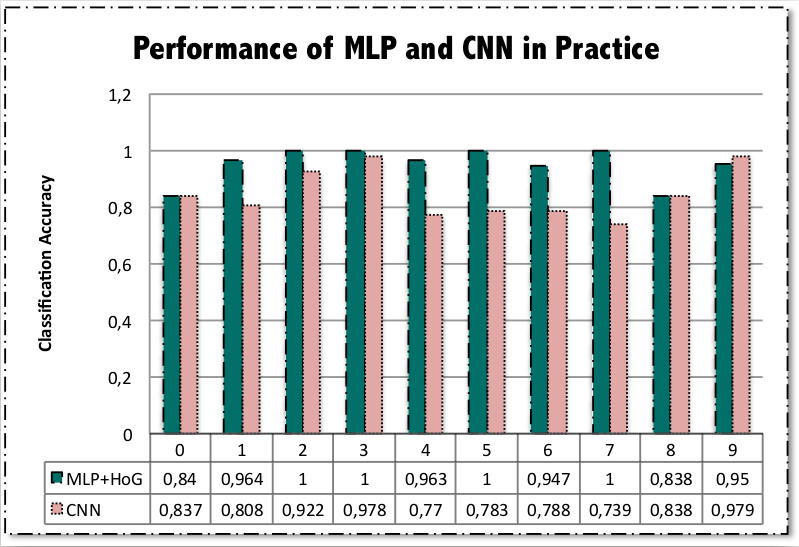
This model is actually not deep enough and it can be dramatically improved by tweaking its structur, i.e. say using ReLU for activation or Batch Normalization to normalize the inputs in each convolution layer.
Conclusion
In contrast to models we introduced in previous sections, deep learning models need less image processing knowledge. The model strucutre has the ability to detect the most important features in inputs on its own.