Shortest Path Problem
Reinforcement Learning is another machine learning algorithm in contrast to models like supervised learning and unsupervised learning. In this problem settings we have an agent and want to achieve some goal. Usually we can not tell the agent how to achieve our goal directly in the environment, in which it i.e. moves, gets some feedbacks after taking an action, for sometimes we do not known the dynamics of this environment or even the environment in this environment is non-deterministic, say, assuming we have an agent to move toward to a target, with 0.8 probability the robot will move correctly as we expecte and with 0.2 the robot will turn a little from left etc. These feedbacks are called Reward. All the training data we use in reinforcement learning is generated by interaction of agent with this environment. Normally the environment can be abstracted as it consists of many states, the state, at which the agent terminates, is called absorb or terminal state. At each time step the agent takes an action and gets a reward. When the agent reaches this absorb state, this episodic task is closed. So our problem turns to finding the optimal action sets that maximize the total rewards along time runs. The strategy to used to find those actions is called policy, with it the agent can reach the terminal state and get many rewards as it’s able to receive. This agent–environment interaction in reinforcement learning is depicted in Fig:
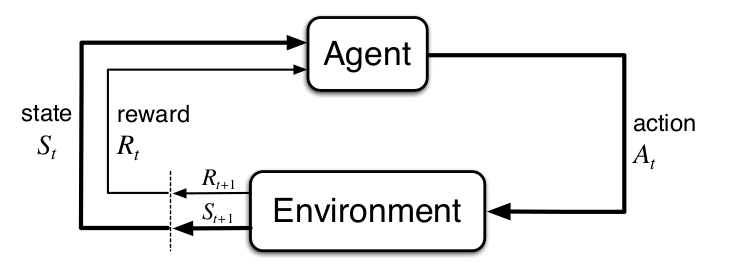
A state signal that succeeds in retaining all relevant information is said to be Markov or it satisfies the Markov Property. Let’s formally define the Markov property by considering how environment might response at time to the action taken at time . In general case this response may depend on what happened in the past:
for all and the events . If the environment responses at time is only depend on the the state and action at time $t$, then this form can be shorted as
for all , then we say this state signal has the Markov property. It enables us to predict the next reward and state at time $t+1$ given the state and action at time $t$. According to this one-step dynamic we can iterate all dynamic history up to now to predict the future dynamics. So the best policy for selecting a action is just as to full this history up to over time changes. Even if the state is not markon, it still can be solved appropriate as to be approximated to a markov state.
A RL task satisfies the Markov property is called Markov Decison Process (MDP), it’s a finite MDP if the state and action are also finite. Given any state and action at time step , the one-step dynamics for next state in MDP is defined in Eq:
The expected next reward at given current state , action is
This is the basis of reinforcement learning task. Moreover, in reinforcement learning tasks all the training data is coming from the interaction of the agent with the environment. So we do not need extra training samples and labels for reinforcement learning.
In the following sections I’ll demonstrate how the basis algorithm in RL I implemented in cs188 projects.