Long Short Term Memory
Introduction
Long Short Term Memory (LSTM) differentiates with RNN only by holding a cell state in each time step. Furthermore the hidden state will be split in four single cell states. These cell states have the ability to add or remove information during time steps, which are organized by special non-linear structures called gates. Let’ walk it though out.
The working flow in LSTM
The evolution of LSTM over time steps is shown as follows:
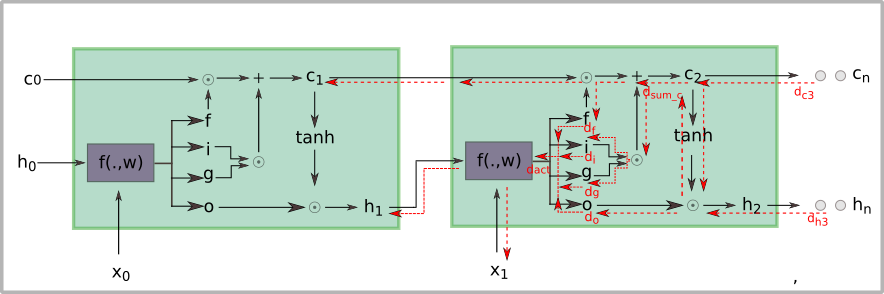
The is an affine operation that calculates the activation vectors. As it depicts here, the activation signals have been split into four slices: input gate , forget gate , output gate and go through gate . The gates are kind of sigmoid functions that maps its inputs to interval and go through gate uses to squashes its inputs to interval so that the output looks more centralized.
Forward phase
In forward propagation phase the input gate decides what we want to process and go through gate determines how much signal we want to let it through. The forget gate gives signals (here previous cell state ) the possibility that it always has been taken into account in next cell state . The squashed new state is merged with output gate ’s outputs for generating new hidden state .
This forward process can be abstracted as the following equations:
where is element-wise product and the gates are just subslices of activation vectors like and etc. denotes the time step. The act here means the activation vectors we got from the function. As forward propagation starts, the initial cell state is initialized as same size of hidden state then all the time evolutions work out iteratively through. Here we also used -Norm as regularization penalty like we always do in neural networks.
Backward phase
In Backward propagatoin phase, the gradients of cell state and hidden state are back propagated in the symmetrical order that got forward propagated. Assume we have the derivate of and as and , now let’s back propagate the errors. Keep in mind that what you calculated in forward propagation should be cached for back propagation and all gradient-flows has exact the invertible direction of forward propagation. Taken and next cell state we got the gradient of previous output gate as follows:
from which we got in the diagram above. Be careful that we did not use for gradient of cause that does not contribute to calculate the . In contrast to this the gradient of next hidden state is a little bit complicated to back propagate. For getting we used and , is derived from , here takes more attention. in above figure coalesces the two flows from cell state and , it’s merged as follows:
after this the gradient flow will be back propagated to continuously. The derivate of forget gate calculated as:
In the same way we got derivate of separately as follow:
As so far we can concatenate all the gate derivatives for assembling the derivate of activation vectors, from which we’ll get the derivative of hidden state’s weight, input to hidden state’s weight as well as the derivate of initial cell state and bias, which is just a couple of matrix multiplication and will not be further explained here.
For overfitting a model we used the same setting as in RNN, the loss of LSTM changes very mildly than RNN. Although the captioning results of both models are nearly same, but the LSTM has an advantage for again Vanishing-gradient problem.
Conclusion
Because of the long dependenciy problem, RNN learns not appropriately as we anticipated. In order to solve this problem we introduce a cell state for dispatching the long dependency information in such a way that the gradeint vanishes not dramtically quick. So the learn process is better than in RNN. Apart from this property, what RNN does, LSTM is also suitable for those case.